Augmenting transferred representations for stock classification
Elizabeth Fons1
Paula Dawson2
Xiao-jun Zeng1
John Keane1
Alexandros Iosifidis3
- 1Department of Computer Science, University of Manchester, UK. 2AllianceBernstein, London, UK. 3Department of Electrical and Computer Engineering, Aarhus University, Denmark.
Abstract
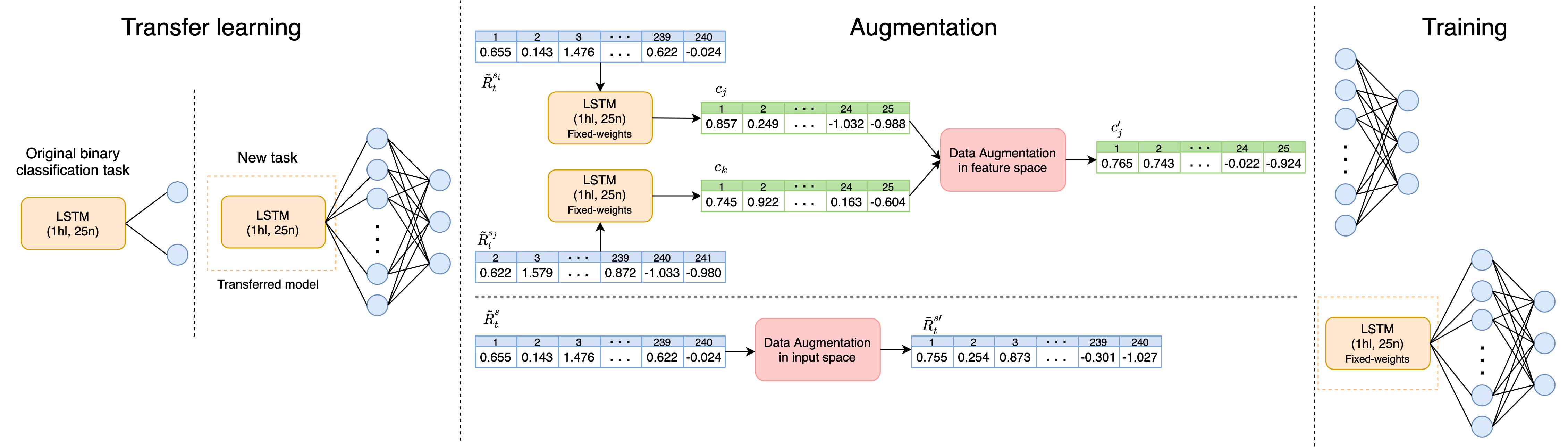
Stock classification is a challenging task due to high levels of noise and volatility of stocks returns. In this paper we show that using transfer learning can help with this task, by pre-training a model to extract universal features on the full universe of stocks of the S
Paper
Bibtex
xxxxxxxxxx@INPROCEEDINGS{9413530,author={Fons, Elizabeth and Dawson, Paula and Zeng, Xiao-jun and Keane, John and Iosifidis, Alexandros},booktitle={ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={Augmenting Transferred Representations for Stock Classification}, year={2021},pages={3915-3919},doi={10.1109/ICASSP39728.2021.9413530}}Acknowledgement
This work was supported by the European Union's Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie Grant Agreement no. 675044 (http://bigdatafinance.eu/), Training for Big Data in Financial Research and Risk Management. A. Iosifidis acknowledges funding from the Independent Research Fund Denmark project DISPA (Project Number: 9041-00004).